
DDN IMEとは:概要、システム構成、アーキテクチャ、データマイグレーション、性能

この記事は、日本計算工学会「計算工学」(Vol.21 No.4 2016)に掲載頂いた「バーストバッファ型IOアクセラレーション製品 DDN IMEのご紹介」の内容となります。
1 はじめに
DataDirect Networks (DDN)社は大規模クラスタ環境向けにストレージアレイおよびLustreやGPFSなどの並列ファイルシステムをソリューションとして提供してきました。DDN IME (Infnite Memory Engine)は、大規模クラスタ環境で従来型のストレージアレイ・並列ファイルシステムでは対応不可能な問題を解決し、アプリケーションのIO性能を更に高速化するツールとしてDDN社によって設計、開発されました。
2 IME 概要
IMEはSSDを搭載した複数台のサーバをクラスタとして構成し、SSDで構成されたキャッシュ領域を計算クラスタに提供し、並列ファイルシステム上のデータへの高速キャッシュアクセスを実現する製品です。並列ファイルシステムと異なるアーキテクチャおよび記憶領域としてSSDを採用することによって、従来のストレージシステムが不得手としてきた、小さいIOサイズでのIO、ランダムアクセスなどの高速化も可能となります。
3 システム構成
DDN IMEは計算ノード上で動作するIMEクライアントと、計算クラスタと並列ファイルシステムの間に配置された複数のIMEサーバから構成されます(図1)。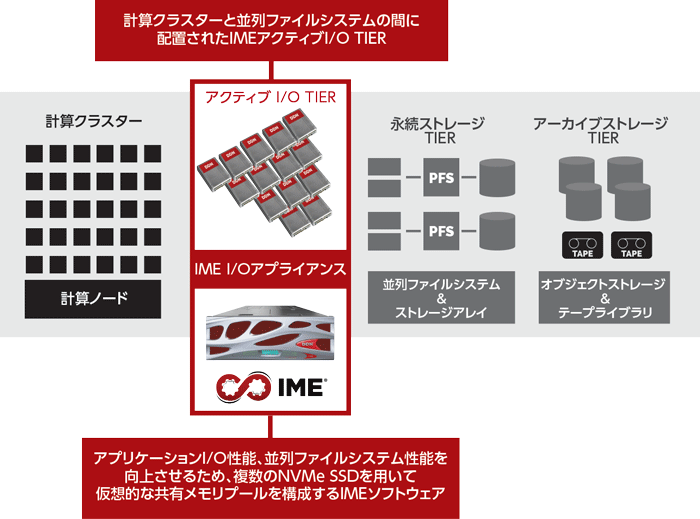
IMEクライアントが動作する計算ノードについては特殊なハードウェアは必要ありません。OS は RHEL7系のOSで動作します。IMEサーバのハードウェアは現時点(※2016年)ではDDNが提供するアプライアンス製品である IME14K(図2)のみのサポートとなります。(※本記事公開時点ではIME240のみ)

IME14K は4Uフォームファクタに2基のIMEサーバを実装しています。各IMEサーバは24基のNVMe SSDを搭載し、Infiniband EDR 6ポートもしくはIntel OmniPath 4ポートを搭載します。IME14K 1基あたり(IMEサーバ x 2)の実効性能はInfiniband利用時で50GB/s、OmniPath利用時で40GB/s となります。
4 アーキテクチャ
DDN IME のアーキテクチャを図3に示します。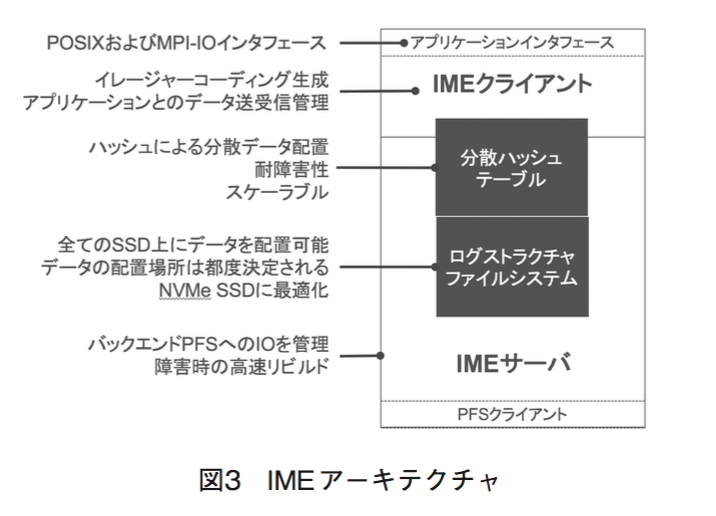
IMEはアプリケーションインタフェースとしてPOSIX および MPI-IO をサポートします。POSIX インタフェースは計算ノード上に IME プールをマウントすることによって実現されます。IME はネームスペースを管理するためのメタデータサーバ機能は有しておらずバックエンドの並列ファイルシステム(PFS)のメタデータ機能を利用します。そのため、計算ノード上でマウントした IME プールとバックエンド PFS のネームスペースは同一のものとなります。
IME クライアントはアプリケーションとIME サーバ間とのデータの送受信を管理します。また、データ保護機能としてイレージャーコーディングをクライアント側で設定することが可能です。IME サーバ上の IMEプールは従来の RAID 機能に相当するデータ保護機能を持ちません。IMEクライアント上では、送信するデータのデータ部およびパリティ部の数を指定し(例えば8D+2P など)、各シェードをそれぞれ別のIME サーバに送信します。IMEサーバ障害およびSSD単体の障害時にはパリティ再計算によるデータ復旧が行われます。
IME は分散ハッシュテーブルによってデータがどのIMEサーバのどのSSDに保持されているかを管理します。分散ハッシュテーブルは全IMEサーバで共有されており、全IMEサーバがデータの位置を把握し、障害復旧にも利用しています。
データはNVMe SSDに対して最適化されたIMEサーバ上のログストラクチャファイルシステムに格納されます。ログストラクチャファイルシステムは分散ハッシュテーブルと連携し、データの格納場所を決定します。
IMEサーバはIMEサーバ上にフラグメントされているデータをバックエンドPFSに最適なサイズのバッファにまとめバックエンドPFSに書き込みます。バックエンドPFSからIMEへの読み込み処理はコマンドの発行が必要です。
5 データマイグレーション
IMEはバックエンドPFSのキャッシュ領域として利用される製品です。バックエンドPFSとのデータのやり取り(マイグレーション)にはステージング方式と透過方式の二通りがあります。ステージング方式の場合、バックエンドPFSからIMEへのデータのロード、IMEからバックエンド PFSへのデータのフラッシュは明示的なコマンドの発行が必要となります。透過方式の場合、アプリケーションから読み込みを行ったデータがIME上に存在しない場合、IMEをバイパスし、バックエンドPFSから直接データを読み込みます。この際、IME 上へのデータのロードは行わない為、IME 上にデータをロードしたい場合は、ステージング方式 と同様に明示的なコマンド発行が必要です。アプリケーションから IME に書き込まれたデータは透過方式では自動的にバックエンドPFSにフラッシュされます。
6 性能
図4にIOスループットベンチマークである IOR を用いたLustreとIMEの性能比較を示します。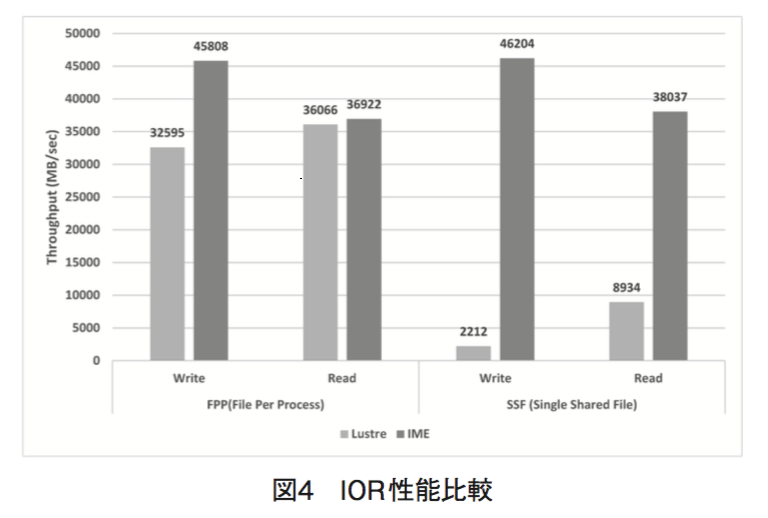
ハードウェア構成はLustreが理論ピーク性能40GB/s、IMEが理論ピーク性能48GB/s の構成です。理論ピーク性能はネットワーク帯域から算出しており、使用しているディスクドライブおよびSSDの合算性能は理論ピーク性能以上の構成です。計測は32基のクライアントを利用し合計512並列、合計ファイルサイズ3.3TB で行いました。 また、生成するファイルについては、FPP (File Per Process)とSSF (Single Shared File)の二通りを実施しました。FPPは並列ファイルシステムが得意とするプロセスごとに異なるファイルを生成する方式であり、SSFは単一ファイルに対して複数プロセスからアクセスするため、ロックのコンテンションが大量に発生し、並列ファイルシステムが不得手とする方式です。SSF の場合、Lustreが全く性能を発揮できないのに対し、IMEはFPPと同等の性能を得られています。IMEのアーキテクチャはSSFであっても、ロックを利用せずスケール可能な実装です。FPPの場合、大規模並列アプリケーションでは使用するファイルの数が膨大になり並列ファイルシステムのメタデータ性能がネックになるため、今後はSSFの利用が考えられますが、従来の並列ファイルシステムとは異なる実装でなければ性能を確保できない問題があり、IME はこれに対する一つの解答です。
7 おわりに
本稿では、最新のIOアクセラレーション製品 DDN IME の概要について紹介致しました。DDNは今後、実アプリケーションでの性能測定、ジョブスケジューラーとの連携、実システムでの運用などを通して、IMEの更なる性能、機能の充実を目指していきます。
出典:一般社団法人日本計算工学会 学会誌「計算工学」(Vol.21 No.4 2016)「バーストバッファ型IOアクセラレーション製品 DDN IMEのご紹介」
筆者:橋爪 信明(はしづめ のぶあき)
株式会社データダイレクト・ネットワークス・ジャパン T3S Director。 サン・マイクロシステムズにて17年間ベンチマークエンジニア、プリセールスエンジニアとして主に HPC 案件に従事した後、2011年データダイレクト・ネットワークス・ジャパン入社。プリセールスエンジニア、プロフェッショナルサービス、カスタマーサポートを統括。







