御社の現状の課題に合ったソリューションをご紹介します。
パフォーマンス・ボトルネック
DDNの超高性能ブロックストレージ、ファイルストレージで、ストレージのパフォーマンス・ボトルネックを解決
2009年、DDNはStorage Fusion Architecture (SFA)を発表しました。SFAは、全く新しいストレージエンジンのためのアーキテクチャであり、前世代S2Aのイノベーションをさらに進化させた設計となっています。今日におけるビッグデータ戦略の根幹となる、必要不可欠な2つのアーキテクチャ要件を実現します。
(1) 様々なワークロードが混在する環境での性能
SFAストレージは、リアルタイムのスループット性能に加えて、HDDおよびSSDに最適化された低遅延アクセスにより、業界最高レベルのIOPS性能を実現しています。
(2) データ保管とデータ処理を融合するインストレージ・プロセッシング
2009年に、DDNはもう1つの業界初のテクノロジー「In-Storage Processing ™ (インストレージ・プロセッシング)」を世に送り出しました。ストレージ機能を処理リソースへ取り込むという従来の発想を逆転させ、処理機能をストレージ・リソースへ取り込みました。このストレージとコンピュートを融合させるという画期的なインストレージ・プロセッシングは、データ処理遅延を削減するほか、プロトコル階層自体を取り除くことが可能となります。このテクノロジーにより、外部サーバーおよび関連するネットワークハードウェアが不要となり、数十ペタバイトクラスの大型ストレージの複雑性とコストを大幅に削減します。
SFAストレージは、SAN、NASおよび最適化された各種並列ファイルシステムへのストレージ・アクセスに対応し、圧倒的なスケーラビリティと性能を両立させたストレージ・アレイ・プラットフォームです。高度に並列化されたストレージ処理テクノロジーが、ビッグデータ/AI環境に対応する圧倒的なIOPSとスループットを同時に実現します。エンタープライズレベルのデータ保護に、業界最高レベルのスケーラビリティ、実装密度、エネルギー効率を最適なバランスで組み合わせることにより、SFAストレージは1TB/秒まで拡張可能なスループット性能と数十ペタバイトのストレージ容量をサポートするとともに、コンパクトで電源効率に優れた設計となり、今日におけるデータセンターの要求に応えています。

これまでにないスケーラビリティ
DDNのスケールアウト・ストレージソリューションで、数時間で数十、数百ペタバイトにストレージを拡張
20年以上にわたり、DDNの革新的なテクノロジーは常に進化し続けており、最も性能要求が厳しい、世界最大規模のビッグデータ/AIシステム環境における課題を解決しています。DDNが培ってきた専門知識と豊富な経験を活用することにより、ビッグデータ/AI環境における各種の問題や制限を解決し、DDNの顧客企業や組織は競合優位性を獲得することに成功してきました。DDNは業界最高レベルの並列ファイルシステム、そして比類ないNAS・SANアプライアンス製品を世に送り出し続けています。迅速なシステム導入のために事前に構成、設定、最適化されたDDNのEXAScalerストレージアプライアンスファミリーは、様々なアプリケーションが求める要件を満たしたスループット性能、IOPS性能、ストレージ容量を提供し、予測不能な将来の変化や成長に対しても、制限なくシステムを拡張することが可能です。
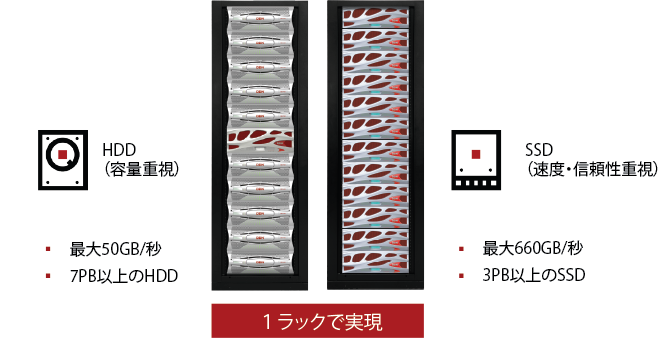
例えば4Uに60ドライブを格納する小規模な構成からスタートし、その後は必要に応じて容易に総容量を拡張可能です。4Uに84ドライブを搭載可能なエンクロージャーを4つまで追加可能な拡張性を持っています。こうして拡張していくことで、全体のTOC を最小化しながら、数GB/秒のI/Oを数百同時実行可能な性能を発揮するPBクラスのシステムに統合することができます。SSDの構成で3PB以上、最大660GB/秒、HDDで構成すれば7PB以上、最大50GB/秒を1ラックで実現可能です。
データセンターのコスト
DDNの業界最高水準のラックあたりの容量とパフォーマンスでストレージ密度を高め、データセンターのコストを最小化
DDNの極めて高密度なストレージをご使用頂くことで、ラック本数を減らすことができ、データセンターにかかるコストを最小化することができます。
アプリケーション高速化
ストレージ性能のリーダーDDNによるNVMeベースのキャッシュ・アプライアンスもしくはフラッシュストレージでアプリケーションを高速化
NVMeベースのキャッシュ・アプライアンス:IME バーストバッファ

NVMeへの移行
従来のフラッシュストレージのほんの一部のコストで、オールフラッシュストレージのパフォーマンス、低レイテンシー、消費電力削減のメリットを享受
DDNの革新的なフラッシュストレージで、最高のコストパフォーマンスでオールフラッシュストレージのメリットを手に入れることができます。

優れたサービス
Intersect360によるHPCユーザー調査でストレージ部門No.1の評価を得ているDDNは、その技術力が高く評価されています。
計画、コンサルティング、導入サービスなどをご提供するプロフェッショナル・サービスや、日本語による様々なサポートにより、システム環境が変化する中においてもストレージ資産を継続的に最適化し、安定的に活用していただくことが可能です。
ソフトウェアディファインドストレージ(SDS)
DDNのソフトウェアディファインドストレージ製品群で、スムーズにメリットを享受
DDNは、SFX Flash Cachingソフトウェア、IMEソフトウェアを提供しています。これらのSDSオプションは、コンセプト検証の迅速化、ストレージの場所や種類の管理を改善し、ハードウェアプラットフォームの選択肢の柔軟性を向上させ、管理に必要な人員を削減してCAPEX / OPEXを削減します。
オブジェクトストレージ
DDNのWeb-Object Scaler (WOS)アプライアンス/ソフトウェアで、オブジェクトストレージの導入を簡素化、高速化、スケール
世界で最もスケーラブルなオブジェクトベースのソフトウェアテクノロジにより、安全でグローバルなマルチサイトコラボレーション、世界中のコンテンツ配信、アクティブアーカイブとディープアーカイブ、リアルタイムレプリケーション、インテリジェントな階層化、およびパブリッククラウドへのブリッジを実現します。
本番環境で既に1/4兆のオブジェクトのプラットフォームとなっているWOSは、従来のファイルストレージやブロックストレージの管理や管理にかかるコストを実質的に排除し、超低TCOを実現する、最も適応性が高く効率的な方法でデータの増大に対応するためのシステムです。

ストレージ統合
DDNの製品とコンサルティング・サービスで、ストレージ資産を統合し簡素化
すべてを単一のプラットフォームで実現することで、データ・インフラ、データ・マネジメント、そしてデータセンターのTCOを最小限に抑えます。

ユビキタス・データ
DDNのウェブスケール・ストレージソリューションで、世界中の複数に散らばるデータにアクセス、共有、レプリケーション
世界で最もスケーラブルなオブジェクトベースのソフトウェアテクノロジーにより、安全でグローバルなマルチサイトコラボレーション、世界中のコンテンツ配信、アクティブアーカイブとディープアーカイブ、リアルタイムレプリケーション、インテリジェントな階層化、およびパブリッククラウドへのブリッジを実現します。
本番環境で既に1/4兆のオブジェクトのプラットフォームとなっているWOSは、従来のファイルストレージやブロックストレージの管理や管理にかかるコストを実質的に排除し、超低TCOを実現する、最も適応性が高く効率的な方法でデータの増大に対応するためのシステムです。
公開日時
