
DDNのAIストレージが、NVIDIAのGPUDirect Storageによりさらに高速かつシンプルに
この記事は、DDN.comに掲載のブログ記事 "DDN AI Storage Gets Faster and Simpler with GPUDirect Storage" の抄訳版です。
DDNのAIストレージが、NVIDIAのGPUDirect Storageによりさらに高速かつシンプルに
NVIDIA DGX A100との組み合わせで、DDNがパフォーマンス記録を更新:
GPUへ直接データを転送する場合の速度は178GB/秒で、NFSの60倍!
システム規模を拡張する過程で、理想的な環境を維持していくためにはどうしたら良いでしょうか?また、データからの価値創出を高速化するためのGPUインフラストラクチャやデータサイエンティスト、データソースおよびインジェスト(データ取得)への投資は、十分な余裕を持って最適化されていますか?
システム規模を拡張する時、シンプルさとパフォーマンスは密接に関係します。サイロ化(孤立)したデータを管理する際の複雑さ、異なるシステムにおける複数のストレージ層、そして拡張性を考慮せずに設計されたストレージアプライアンスは、AIプロジェクトにとって重大なリスク要因になる可能性があります。
DDNは世界的に大規模な環境で実際にストレージを稼働させた数多くの実績を誇るベンダーですが、NFSソリューションなどのエンタープライズプロトコルは、小規模なワークロード向けに設計されているため、規模が大きくなると管理が非常に難しくなり、最終的には拡張が不可能になる危険性を孕んでいます。ROCEなどの高速化テクノロジーを使用したとしても、NFSはGPUで実行されるアプリケーションのボトルネックになり得ます。本ブログでは、DDNのデータプラットフォームとNVIDIA DGX A100システムを最大限に活用するために、DDNとNVIDIAの両社が緊密に協力して行った高度な技術開発について解説します。
◆最適化されたAIストレージインフラストラクチャ◆
コンピューティングパフォーマンスを最大化
DDN AI400Xベースのソリューションは、単独のNVIDIA DGX A100に最大178GB/sでデータを供給
簡単かつシームレスに拡張
DDN AI400Xベースのソリューションは、単独のNVIDIA DGX A100への投資効果を最大化。最大280クライアントのDGX A100を搭載したNVIDIA SuperPODでの動作が実証済み
実環境で証明済み
DDNは革新と発見を牽引するデータ集約型の組織に数十年間にわたりストレージを提供してきた実績を保持
組織は、AIプロジェクトから価値を引き出し、競争力を高めなければなりません。それと同様にデータインフラストラクチャは、インフラストラクチャ投資と手動によるデータ移動を最小限に抑えつつも、AIワークフローに最大限のパフォーマンスを提供する必要があります。DDN A3Iストレージは、構成の複雑さとAIインフラストラクチャを最小限に抑え、他社が提供するストレージよりも優れたパフォーマンスを提供することが実証されています。
DDNは数十年にわたって世界最大レベルの複数のコンピューティングセンターにストレージソリューションを提供してきました。その最新の実績の1つがNVIDIAのSeleneです。Top500ランキングで5位にランクされたシステムであり、現在稼働しているNVIDIA DGX A100のSuperPODとしては最大のものです。Seleneクラスターは、280台のDGX A100システムで構成されています。これらのGPUベースのシステムを含むすべてのGPUコンピューティングプラットフォームは、膨大な量のデータを処理する方法に大きな変革をもたらしました。
NVIDIAのGPUは大規模な同時処理の機能を提供し、DDNの共有並列アーキテクチャは、GPUを使用した最大規模のシステムにおいても、あらゆるタイプの非構造化データワークロード(大規模、小規模、および混合ファイルタイプ環境)に十分なデータを供給できることが証明されています。これによりDDN A3Iストレージソリューションは、ディープラーニングや推論などのエンドツーエンドのAIワークフローを確実に処理できる理想的なデータプラットフォームになります。実際にDDNは、数百ペタバイトの容量を持ちテラバイト/秒でデータを提供するデータプラットフォームを備えた世界最大の自動運転プログラムを支えている実績を持ちます。
DDNとNVIDIAは、この成功に満足せず、常にAIワークフローのパフォーマンス向上の方法を模索しています。これを実現するために私たちが共同で作業している方法の1つに、NVIDIAのMagnum IO APIセットの一部であるGPUDirect Storage(以下GDS)の使用があります。
GDSは、より高速で直接的なデータパスにより、ストレージとGPU間のデータ移動の効率を向上させます。データは、システムメモリやCPUを経由せずに、ホスト上のネットワークインターフェースカード(NIC)からGPUに直接転送されます。これにより、システムアーキテクチャからI/Oパスのボトルネックを排除し、不要なデータコピーを無くし、低いレイテンシーを実現します。このことがCPUリソースを解放し、ディープラーニングアプリケーションへのデータを取り込んでいる間に、画像処理などの他のタスクを実行することを可能にします。
NVIDIA DGX A100システムには、8つのシングルポートMellanox ConnectX6ネットワークインターフェースが装備されています。2つのGPUと2つのNICを持つPCIスイッチが4基、相互に接続され、NVIDIA DGX A100内のトラフィックを管理します。そして4基のPCIスイッチは、2つのAMD CPUを介して相互接続されています。DDNではGDSと共有並列アーキテクチャが完全に統合されており、データは最も近いインターフェースを通して直接転送されるため、データパスの管理は他社製品よりも優れていると言えます。DDN A3IストレージとGDSの組み合わせにより、データはアプリケーションとストレージの間で可能な限り最短で最も効率的な経路を経由することが保証されます。
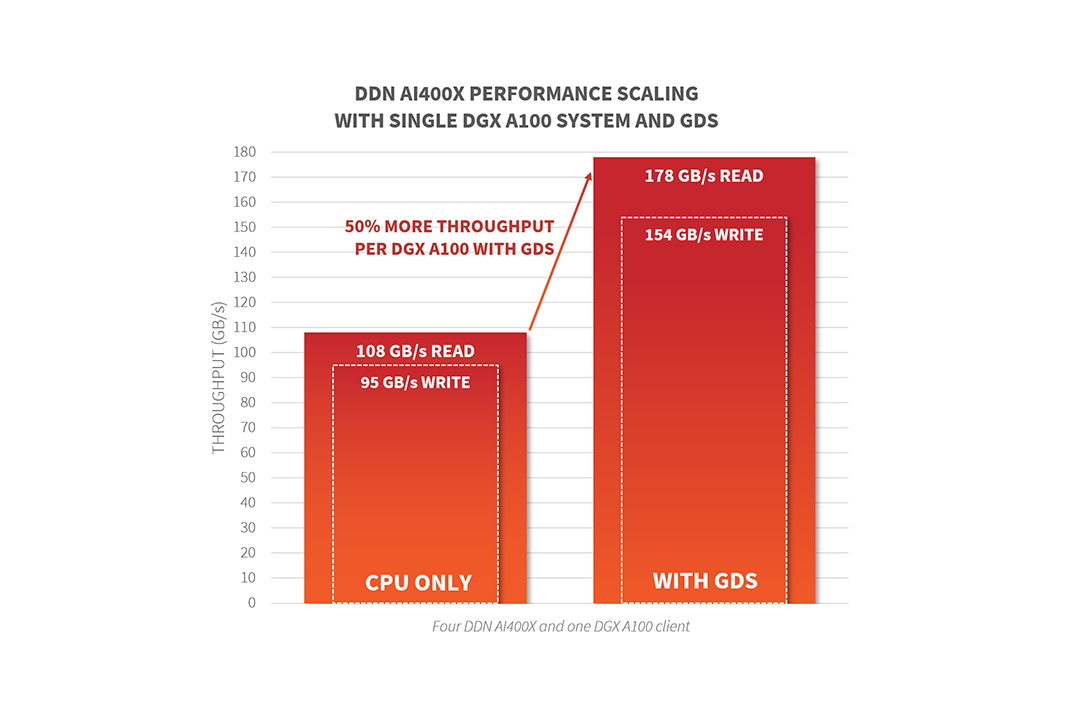
DDNのラボでは、4台のDDN AI400Xアプライアンス(過去6か月間に出荷してきたものと同じアプライアンスと構成)を、HDR 200 Infinibandネットワークを介して1台のNVIDIA DGX A100システムに接続して検証を行いました。GPUに最も近いNVIDIA DGX A100システム上の8つのシングルポートNICすべてを接続し、最初にCPUの標準I/Oパス経由で、次にGDSを有効にして最適化されたI/Oパス経由で、8つのGPUすべてを使用してパフォーマンスを測定しました。
その結果の中から、非常に興味深いポイントを3つご紹介します。
1. GDSをサポートするGPUに対して直接、178GB/sの読み込みパフォーマンスと154GB/sの書き込みパフォーマンスを実現
これは、8つのHDR200 NICが出せる最大速度にほぼ等しく、NFSなどのエンタープライズファイル共有プロトコルが実現できるパフォーマンスの60倍に達します。DDNの共有並列アーキテクチャは無制限に拡張が可能で、PODやSuperPODでのデプロイメントなどのように、複数のシステムを同時に使用してこのレベルのパフォーマンスを簡単に実現することができます。
2. GDSを使用すると、CPUを経由する従来のパスと比較して、50%高いスループットを実現
DDNではCPUパスを介したパフォーマンスも非常に高く、単独クライアントからの読み込みのスループットは108GB/秒です。しかし、CPUを経由するデータパスにはDGXシステムの制限があるため、NVIDIA DGX A100のGPUで最大限のデータ転送を実現するためにはGDSが必要です。
3. GDSはDDN AI400Xアプライアンスに完全に統合
8つのGPUで実行されたパフォーマンスベンチマークアプリケーションは、そのままでGDS機能をシームレスに利用することができました。NVIDIA DGX A100システムは、即座に178GB/sのパフォーマンスを利用できます。そしてこれには、追加のライセンスやコストは必要ありません。
共有並列アーキテクチャがどのように進化してきたかを振り返るのは、非常に興味深いものです。DDN A3Iストレージソリューションは、NVIDIA DGX A100のような単独のスーパーコンピューターとNVIDIA SuperPODのような多くのクライアントを備えた大規模なスーパーコンピューティングクラスターの両方に、高いスループット、低いレイテンシ、大規模な同時実行性の元でデータを供給し、規模を問わず様々なシステムに最大限の柔軟性と処理能力を提供できることが証明されています。DDN A3Iアプライアンスは独自のMultiRailアルゴリズムを使用することでネットワークトラフィックのバランスを自動的に取り、最適化された高性能ネットワークを容易かつ即座に使うことを可能にします。
NVIDIAのGPUとNVIDIA DGX A100の組み合わせでAIとHPCを大規模に展開されていますか?GDSをサポートしたDDNのデータプラットフォームがGPUで実行されているアプリケーションから最大のパフォーマンスを得るのにどのように役立っているか是非一度ご説明の機会を頂ければと思います。
お問い合わせはこちらから https://ddn.co.jp/contact.html
DDN A3Iソリューションについてはこちらから https://ddn.co.jp/products/ai_storage/a3i.html







